
Semantic image synthesis (SIS) shows good promises for sensor simulation. However, current best practices in this field, based on GANs, have not yet reached the desired level of quality. As latent diffusion models make significant strides in image generation, we are prompted to evaluate ControlNet, a notable method for its dense control capabilities. Our investigation uncovered two primary issues with its results: the presence of weird sub-structures within large semantic areas and the misalignment of content with the semantic mask. Through empirical study, we pinpointed the cause of these problems as a mismatch between the noised training data distribution and the standard normal prior applied at the inference stage. To address this challenge, we developed specific noise priors for SIS, encompassing spatial, categorical, and a novel spatial-categorical joint prior for inference. This approach, which we have named SCP-Diff, has yielded exceptional results, achieving an FID of 10.53 on Cityscapes and 12.66 on ADE20K.
Our code release is undergoing a review process within the company of our co-authors due to regulations.
If you meet with problems when trying to reproduce our results or have problems with our implementation, feel free to contact us :)
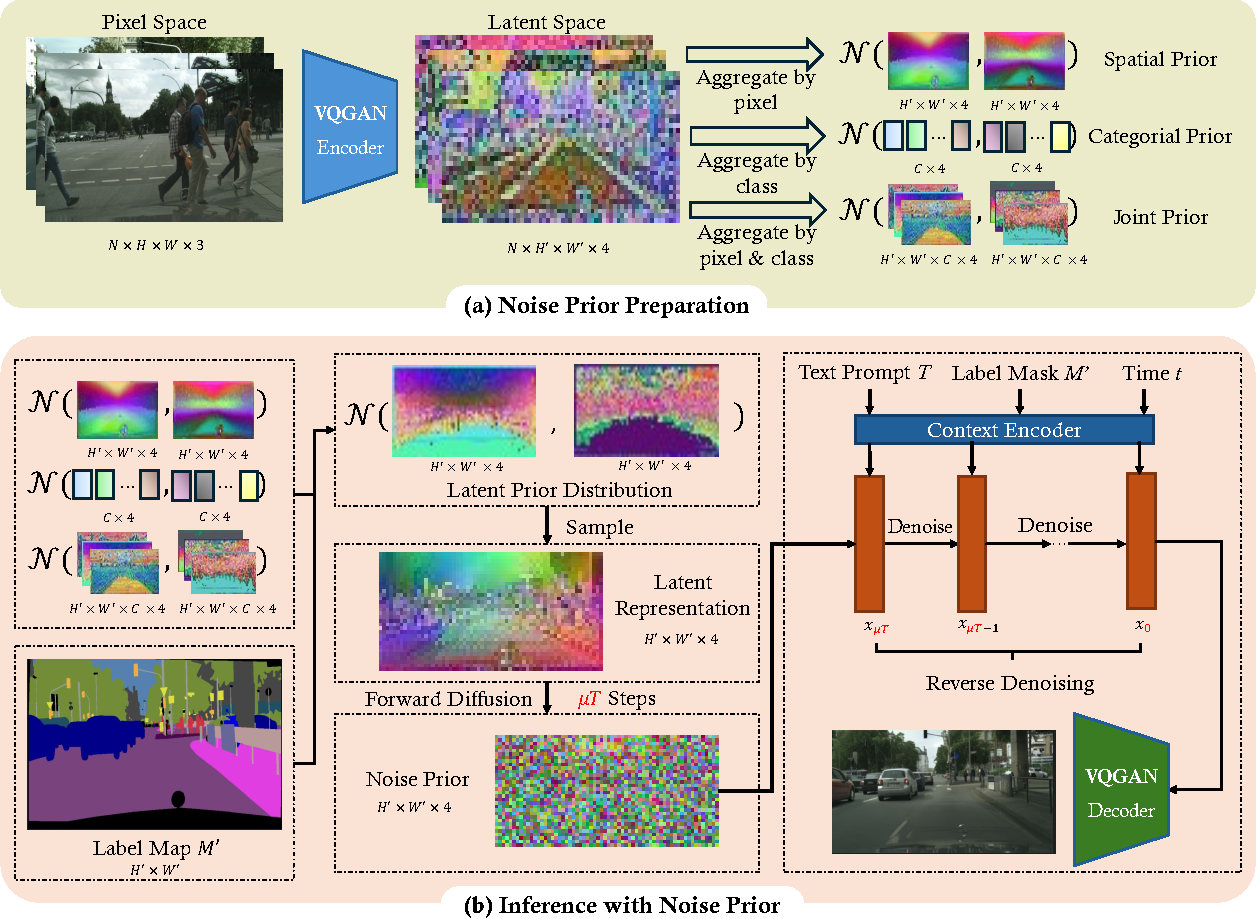
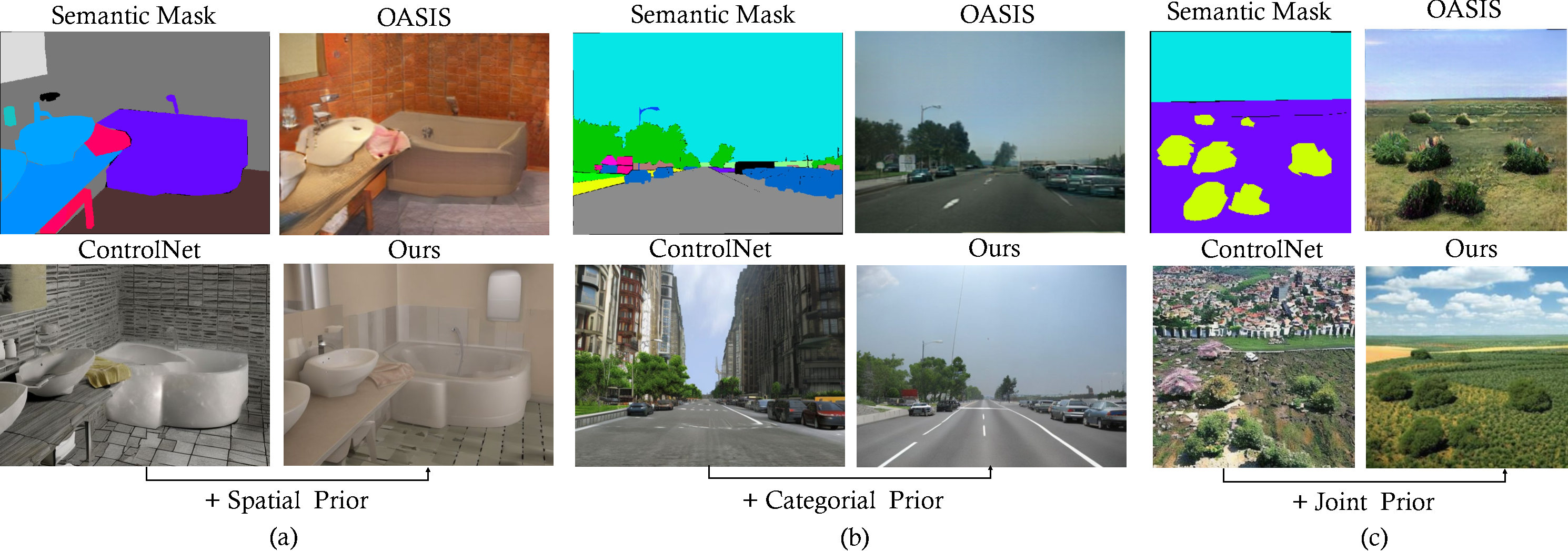

















| Method | Cityscapes | ADE20K | ||||
|---|---|---|---|---|---|---|
| mIoU ↑ | Acc ↑ | FID ↓ | mIoU ↑ | Acc ↑ | FID ↓ | |
| Normal Prior | 65.14 (+0.00) | 94.14 (+0.00) | 23.35 (+0.00) | 20.73 (+0.00) | 61.14 (+0.00) | 20.58 (+0.00) |
| Spatial Prior | 66.77 (+1.63) | 94.29 (+0.15) | 12.83 (-10.52) | 20.86 (+0.13) | 64.46 (+3.32) | 16.03 (-4.55) |
| Categorical Prior | 66.86 (+1.72) | 94.54 (+0.40) | 11.63 (-11.72) | 21.86 (+1.13) | 66.63 (+5.49) | 16.56 (-4.02) |
| Joint Prior | 67.92 (+2.78) | 94.65 (+0.51) | 10.53 (-12.82) | 25.61 (+4.88) | 71.79 (+10.65) | 12.66 (-7.92) |
@article{gao2024scp,
title={SCP-Diff: Photo-Realistic Semantic Image Synthesis with Spatial-Categorical Joint Prior},
author={Gao, Huan-ang and Gao, Mingju and Li, Jiaju and Li, Wenyi and Zhi, Rong and Tang, Hao and Zhao, Hao},
journal={arXiv preprint arXiv:2403.09638},
year={2024}
}